Hiding Files in ZIP Archives
I remember seeing a tool many years ago that could hide other files in BMP image files. I was a bit too young to understand how it worked, but I think I understand the trick now:
- Understand the structure of the file type at the byte level.
- Find a spot that can hold an arbitrary length of data.
- Sneak in whatever you want in there.
As a proof of concept, I used Go to make Sneak - a program to add or extract a hidden file in a ZIP archive.
You can find the source code for it on GitHub.
This is an opportunity to understand the byte structure of a file type. If what you want to do is hide files privately, this isn’t exactly very useful.
In this blog post, we will discuss the original ZIP format. Not the ZIP64 format introduced to work around limitations like the 4 GB limit and more.
ZIP File Structure

A ZIP file looks something like this:

Each file in a ZIP archive has a header followed immediately by the compressed data. This header is known as the Local File Header.
Right after all the files, there are additional headers for each file. These headers are called the Central Directory File Header. ZIP format claims that this repetition of file metadata protects against data loss.
And at the very end is the End of Central Directory Record.
It is worth noting that these headers contain byte offsets of other headers. We will have to take that into account if we are to move things around.
Spot for Our File
ZIP archive software can make certain assumptions about the structure of a ZIP file.
One assumption is that the End of Central Directory Record would be the last thing a ZIP file has. It means we cannot sneak a file at the end of the archive.
We could prepend a file to the beginning of a ZIP archive, but there are a few issues with this approach. One of the most notable is that some software uses the first 512 bytes (known as the magic bytes) of a file to determine its type.
We could sneak our file in between one of the file entries at the beginning of the ZIP archive. But that would mean we are assuming there are multiple files in our archive. And it would also require us to rewrite the Central Directory File Headers. The Central Directory File Headers contain fields that point back to the positions of the Local File Headers.

A sneak spot in the ZIP archive would be right before the first Central Directory File Header. The only bit in the format that holds the byte offset to this header is the End of Central Directory Record.
If we move the Central Directory File Headers to make a spot for our file we only need to update the byte offset for this first Central Directory File Header stored in the End of Central Directory Record.
End of Central Directory Record
The End of Central Directory Record consists of 9 fields.
| Field | Offset | Size |
|---|---|---|
| Signature | 0 | 4 |
| Disk Number | 4 | 2 |
| Central Directory Start Disk Number | 6 | 2 |
| Central Directory Header Count on Current Disk | 8 | 2 |
| Central Directory Header Total Count | 10 | 2 |
| Central Directory Size | 12 | 4 |
| Central Directory Start Offset | 16 | 4 |
| Comment Length | 20 | 2 |
| Comment | 22 | {Comment Length} |
All we need to do is add to the Central Directory Start Offset field the number of bytes we are sneaking into the ZIP file.
Finding the End of Central Directory Record
The total size of an End of Central Directory Record is variable. This is because of the Comment field. The length of the comment is stored in the End of Central Directory Record itself.
But with a bit of intuition, you can figure out what the maximum possible size of this record can be.
The comment length is stored in a 2-byte field. That is 16 bits. The longest comment possible is:
The maximum possible size of the record is:
That is the sum of the offset of the Comment field and its maximum possible length. Which is roughly 65 kB.
Since the End of Central Directory Record is stored at the end of the ZIP file, you can start by scanning, let’s say, the last 1 kB of the ZIP file. If the End of Central Directory Record is not found in that region, then scan the last 65 kB. This is the behaviour you can observe in Go’s implementation of the archive/zip standard package.
The End of Central Directory Record can be identified by its signature 0x06054b50.
Calculating the New Central Directory Start Offset
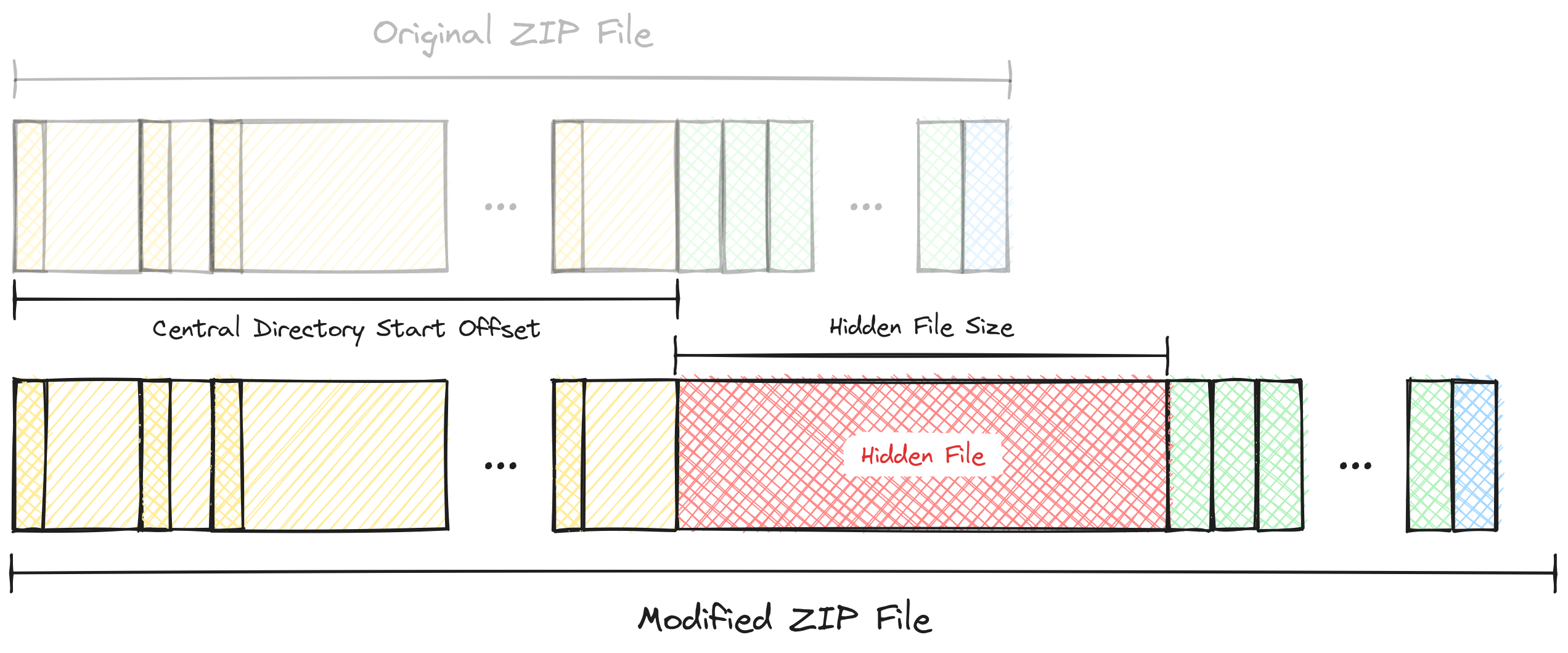
The new Central Directory Start Offset value can be calculated by taking the unmodified value and adding the size of the hidden file to it.
After finding the End of Central Directory Start Offset, take the value of the Central Directory Start Offset field and add the size of the hidden file to it to calculate the new value. Then replace the old value with the new value.
Finding The Hidden File
Given a modified ZIP file, you can go through all the Central Directory Headers until you find the one pointing to the last Local File Header.
Each Central Directory Header consists of 20 fields.
| Field | Offset | Size |
|---|---|---|
| Signature | 0 | 4 |
| Version | 4 | 2 |
| Minimum Version to Extract | 6 | 2 |
| General Purpose Bit Flag | 8 | 2 |
| Compression Method | 10 | 2 |
| Last Modification Time | 12 | 2 |
| Last Modification Date | 14 | 2 |
| Uncompressed Data CRC-32 | 16 | 4 |
| Compressed Size | 20 | 4 |
| Uncompressed Size | 24 | 4 |
| Filename Length | 28 | 2 |
| Extra Field Length | 30 | 2 |
| File Comment Length | 32 | 2 |
| File Start Disk Number | 34 | 2 |
| Internal File Attributes | 36 | 2 |
| External File Attributes | 38 | 4 |
| Local File Header Offset | 42 | 4 |
| Filename | 46 | {Filename Length} |
| Extra field | 46 + {Filename Length} | {Extra Field Length} |
| File comment | 46 + {Filename Length} + {Extra Field Length} | {Comment Length} |
The field we are interested in is Local File Header Offset.
We have to find the largest value of this field across all Central Directory Header. That would point to the last Local File Header.
From there, you can jump to the end of the compressed data and find the hidden file.
The hidden file would start from the end of the uncompressed data region of the last file and end right before the first Central Directory File Header.
Wrap Up
It is worth repeating: If you want to store files privately, this is not what you want to do.
This blog post only briefly outlines the structure of the ZIP file without making it sound like a specification. And demonstrate an example of how one may hide files in other files by taking advantage of the structure of the container format.
This post is 45th of my #100DaysToOffload challenge. Want to get involved? Find out more at 100daystooffload.com.
comments powered by Disqus